依马狮原创
麻省理工学院研究团队从静止图片产生视频
美国麻省理工学院科学家使用机器学习能力从一个静止镜头产生视频。 在我们的生成试验中,我们显示我们的模型能够产生带看似可信的运动的场景, Carl Vondrick、Ham
美国麻省理工学院科学家使用机器学习能力从一个静止镜头产生视频。
“在我们的生成试验中,我们显示我们的模型能够产生带看似可信的运动的场景,” Carl Vondrick、Hamed Pirsiavash和Antonio Torralba在一篇即将在下周的“神经信息处理系统研讨会”上介绍的论文中写道,“我们进行了一个心里物理研究,请100多人比较产生的视频,人们更多地选择来自我们的全模型的视频。”

该团队从建立一种算法开始,大约两年内“观看”200万随机视频,以学习场景动态特性,并利用该知识产生视频。
“我们使用了大量无标记的视频训练我们的模型。我们通过查询流行的网络相册Flickr标签以及查询最常用的英语单词,从Flickr下载了超过200万视频。”
这些视频被分为两组数据:一组未过滤,另一种经过过滤用于场景分类,使用了其中4类——高尔夫球场、婴儿、海滩和火车站。这些视频被运动稳定,因此可更容易地将静态背景与运动中的前景物体区分开来。
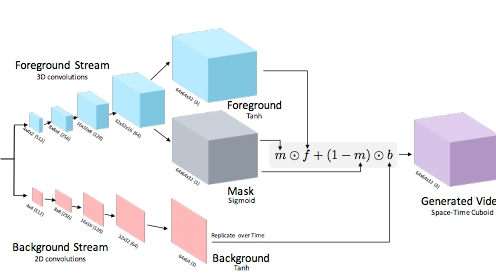
这使研究人员建立一种双码流视频生成架构(如图示),产生一个“每个像素位置和时间标记的前景或背景模型”——一种反映视频压缩编解码“再利用”静态场景元素内像素的方式的方法。
此视频发生器产生时长稍长于1秒的32帧视频,64x64分辨率。这些视频被一个鉴别网络运行,从合成产生场景中辨别现实场景。这用来进一步指示算法产生“看似可信的”运动,“Motherboard”网站称之为“远远超过此领域以前的工作。”




